Originally published on Medium.
Introduction
League of Legends is one of the most played games in the world. Two teams of five players are each armed with one of over one hundred unique champions. Champions are the heroes of the game. Most people only pilot a handful of champions — this is called a champion pool. By focusing on only a few playable characters, it helps players improve more quickly.
The Problem:
I want to be as good at the game as possible BUT I have limited time. How can I choose the correct subset of champions to focus on playing?
Before the game starts, the teams alternate between picking champions. If you pick later in the draft you can chose a character that counters the enemy character (known as ‘counter-picking’).
Champions have favorable and unfavorable matchups. So if you only have one champion option, you leave yourself open to the possibility of some gnarly games.
I currently play an immobile mage named Viktor that excels late in the game but is weak to assassins and long range poke champions. I want to add a champion or two that compliment him.

My Solution:
Create an algorithm (or script) using Python that gives me the best chance to win at my skill level (e.g. rank) by picking champions that when combined have the best matchups. Thus creating the mathematically ideal champion pool.
I started by creating a matrix with the win % data and play % data for every champion in my role (mid). Note: some matchups with very few matches are missing.
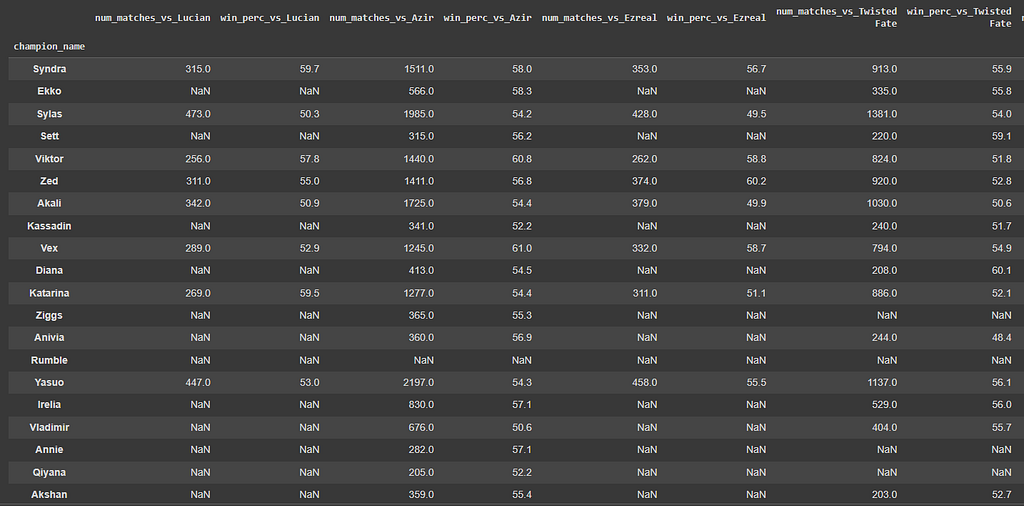
Then I created a way of evaluating how a pool would fair verse a given champion. So say I’m facing an Ahri, and I’m considering a pool of Viktor and Zed. Viktor wins 53% and Zed wins 52% of the time vs Ahri. So obviously I’d pick Viktor if that was my champion pool, scoring me an expected win probability of 53%.
def ScoreAgainstChamp(vs_champ_name=“Ahri”, pool=[“Viktor”, “Zed”]):
win_percs = []
vs_champ_row = df.loc[vs_champ_name]
for champ in pool:
win_percs.append(100-vs_champ_row[“win_perc_vs_” + champ])
win_percs = np.array(win_percs)
return np.max(win_percs)
Then I repeat this against every champ I expect to face, weighing more popular champs more heavily (since I face them more often), and arriving at a single probability for a given champion pool.
def ScorePool(pool=[“Viktor”, “Zed”]):
total_score = 0
for vs_champ in df.index:
vs_ratio = df.loc[vs_champ, “ratio_of_matches”]
vs_score = ScoreAgainstChamp(vs_champ_name=vs_champ, pool=pool)
if np.isnan(vs_score):
vs_score = 50
vs_score_weighted = vs_score*vs_ratio
total_score += vs_score_weighted
return total_score
Some example outputs:
>>> ScorePool([“Viktor”, “Sylas”])
52.02681455756977
>>> ScorePool([“Viktor”, “Zed”])
52.0516233537141
>>> ScorePool([“Viktor”, “Ryze”])
51.72665018207699
So clearly a big improvement from 52.02% to 52.05% 😂
Python has a handy built-in way of creating combinations. So this can be scaled up to any champ
from itertools import combinations
possible_pools = list(combinations(df.index, 2))
>>> for pools in possible_pools:
print(pools, ScorePool(pools))
#skipping a lot of rows
.
.
.
(‘Viktor’, ‘Orianna’) 51.56859170268836
(‘Viktor’, ‘LeBlanc’) 51.86511779016509
(‘Viktor’, “Vel’Koz”) 51.695186233935964
(‘Viktor’, ‘Lux’) 52.142763029933015
(‘Viktor’, ‘Azir’) 51.748084402735294
(‘Viktor’, ‘Lissandra’) 51.66312135500873
(‘Viktor’, ‘Talon’) 51.838008043907095
(‘Viktor’, ‘Galio’) 52.00403361138296
(‘Viktor’, ‘Fizz’) 53.01240768067347
(‘Viktor’, ‘Pantheon’) 52.32903721610868
(‘Viktor’, ‘Heimerdinger’) 53.180298440610976
(‘Viktor’, ‘Tristana’) 52.758282125775786
(‘Zed’, ‘Akali’) 50.4606908188403
(‘Zed’, ‘Kassadin’) 50.8849285037167
(‘Zed’, ‘Vex’) 51.986729578078354
(‘Zed’, ‘Diana’) 51.94402741432256
(‘Zed’, ‘Katarina’) 50.680441709284246
(‘Zed’, ‘Ziggs’) 50.801770150416765
(‘Zed’, ‘Anivia’) 51.55647804491947
(‘Zed’, ‘Rumble’) 50.975257837594064
(‘Zed’, ‘Yasuo’) 50.58753004193754
(‘Zed’, ‘Irelia’) 51.14098152846507
(‘Zed’, ‘Vladimir’) 51.31458051730116
(‘Zed’, ‘Annie’) 51.11831489043167
(‘Zed’, ‘Qiyana’) 50.1288243072024
(‘Zed’, ‘Akshan’) 50.69238847592197
.
.
.
#and the list goes on and on
Other Problems with My Solution
Sample size:
Imagine Twitch has a 85% win rate vs Orianna, that sounds great right? But if there are only 100 games played, I can’t trust that if more games were played that win percentage wouldn’t shrink. Smaller samples are more noisy and harder to generalize.
A frequentist approach could use a bias coefficient like ridge-regression to bias towards a 50% win rate based.
The Bayesian view is similar: create a prior expected win rate of 50% for every champion and update those estimates slightly for each game. So more games grants more insight into the true underlying probability distribution.
Flawed data:
I’m working with the most recent patch 12.20 which came out a day ago and so there aren’t many games. By choosing a larger sample I might get more interesting results.
Conclusion
Ultimately (unless an esports competitor or content creator) video games are played for fun! Problem solving to optimize my ability to play games using computer science and data is fun for me, but the discernible difference of win rate is negligible for small pools (using this dataset).